




Data from NIRS1 are processed mathematically, via chemometric approaches2, generally using a Partial Least Squares (PLS)-type model. This linear methodology is aimed at establishing a statistical relationship, represented by the maximum covariance, between an explanatory variable X and a response variable y. It has been successfully used at IFPEN to predict the properties of oil products and, in recent years, it has mirrored the evolution of new energy technologies (NET) for applications in fields such as bio-fuels and the chemical recycling of plastics.
The approach is based on signal pre-processing operations aimed at correcting analytical artefacts impacting the relevance of models from the use of experimental data. However, in a constantly evolving field requiring more regular model updating, this solution is no longer considered satisfactory.
Deep learning, a promising alternative for the development of experimental models, is the focus of PhD research currently underway3. In this approach, a neural network extracts information from data without the need to explicitly specify how to do so. An error calculated4 between the prediction of the model and the expected value for the response variable makes it possible to optimize the internal parameters of the neural network. This is a complete paradigm shift from chemometrics where it is necessary to develop an experimental design and test different signal processing combinations.
Research at IFPEN has focused on deep convolutional networks, with the goal of developing its own - Inception for Petroleum Analysis (IPA) - to better meet the day-to-day needs of NIRS [1] analysis . This is inspired by the state of the art in deep learning for computer vision and is based on several computational blocks whose architecture is described in Figure 1.

Through comparison with a traditional chemometric model (PLS) and with a deep learning model, DeepSpectra [2] taken as a reference, the IPA model was tested for its capacity to predict the cetane number5 of middle distillates produced using a variety of industrial processes. All three were first of all trained on a set of 174 NIRS spectra, recorded in the 4,000-12,000 cm-1 spectral range and then tested for validation on another base of 75 spectra. In these bases, the cetane number varied between 19.0 and 71.1, with an average of 43.3 and a standard deviation of 11.1. The spectral range was initially reduced to remove NIR bands between 4,000-4,500 cm-1, saturated and affected by problems of non-linearity. The PLS model required a signal pre-processing step prior to calibration incorporating a baseline correction, in contrast to calibration of the IPA model, which is done directly on the data without the need for pre-processing.
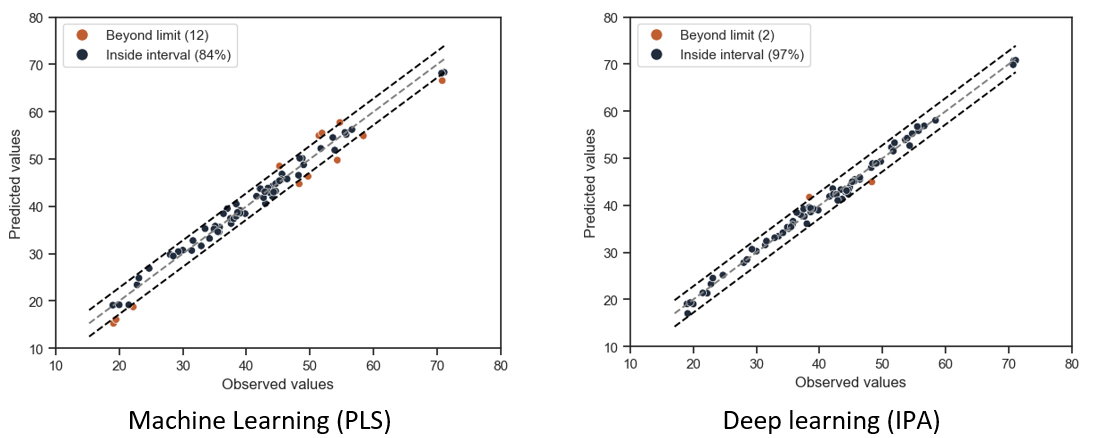
Model quality is generally assessed using several distances, particularly the square root of the mean quadratic error, calculated between model predictions and measured values. For the reduced spectral range, between 4,500 and 12,000 cm-1, the IPA model presented an error 40% lower than the PLS model, and was 20% more accurate than the DeepSpectra deep learning model. Moreover, in two cetane number zones with little information in terms of calibration6, a significant prediction difference between the different models was observed (Figure 2): these are the outermost parts of the validation base parity plot, where IPA proposes relevant predictors while the PLS model lacks precision (as does DeepSpectra, not shown here). Finally, for the same set of data, taking into account the complete 4,000-12,000 cm-1 spectral range, IPA was 50% more precise than PLS and 21% more precise than DeepSpectra.
The superior performances of the IPA model demonstrate its ability to capture more relevant information than the PLS and DeepSpectra models, particularly in the complete spectral range and it can do so without being affected by the saturated part. Similarly, within the range of extreme values considered, IPA performed well at generalizing information across a wide range of predicted property values, unlike the PLS and DeepSpectra models.
1- Abbreviation for Near Infrared Spectroscopy
2- Chemometrics is the application of mathematical tools, particularly statistical ones, to obtain maximum information from physicochemical analysis data.
3- Thesis by F. Haffner, Apprentissage profond et proche infrarouge pour intensifier l'usage des méthodes spectroscopiques (Deep learning and near infrared to intensify the use of spectroscopic methods).
4- Based on a loss function.
5- Number used to precisely evaluate a diesel’s ignition delay.
6- Cetane numbers of 18 to 20 and 70 to 72.
References:
- F. HAFFNER, M. LACOUE-NEGRE, A. PIRAYRE, D. GONÇALVES, J. GORNAY and M. MOREAUD, IPA: A deep CNN based on Inception for Petroleum Analysis, Fuel, Publication submitted.
- X. ZHANG et al., DeepSpectra: An end-to-end deep learning approach for quantitative spectral analysis, Analytica chimica acta, 2019
>> DOI: 10.1016/j.aca.2019.01.002
Scientific contacts: Maxime Moreaud (deep learning) and marion.lacoue-negre@ifpen.fr (near infrared, chemometrics)
You may also be interested in

Deep learning in the field of thermodynamics
Reactive fluid transport simulation has multiple applications - flows in porous media, combustion, process engineering - and requires thermodynamic equilibrium calculations (also knows as “flash” calculations). However, these calculations can take a long time and, as they are involved in large numbers in the simulations carried out, in practice they limit the latter to systems containing few chemical species or to restricted time and space scales...

Semantic segmentation through deep learning in materials sciences
Semantic segmentation conducted on microscopy images is a processing operation carried out to quantify a material’s porosity and its heterogeneity. It is aimed at classifying every pixel within the image (on the basis of degree of heterogeneity and porosity). However, for some materials (such as aluminas employed for catalysis), it is very difficult or even impossible using a traditional image processing approach, since porosity differences are characterized by small contrasts and complex textural variations. One way of overcoming this obstacle is to tackle semantic segmentation via deep learning, using a convolutional neural network.

Transfer learning for process optimization
IFPEN is a global leader in the development of catalysts and processes for clean fuel production. For these processes themselves to be eco-efficient1, it is necessary to optimize the coupling of catalysts with the operating conditions, as a function of the feedstocks used and the target specifications for the refined products. It is therefore useful to be able to draw on predictive models for the performance achieved, and machine learning can help improving these models...